
- 분류 전체보기 (744)

- PROGRAMMING (439)
- JAVA (11)
- JAVA SPRING (13)
- PYTHON (0)
- JAVASCRIPT (21)
- React (70)
- HTML (0)
- Next.JS (1)
- CSS (2)
- DB (Oracle, MongoDB, etc.) (1)
- 깃허브 (31)
- 백엔드 (2)
- 프로젝트 (24)
- 슈퍼코딩 강의 정리 (125)
- ERROR (5)
- 단축키 기타 (1)
- 리눅스 (2)
- LEETCODE (1)
- 정보처리기사 (1)
- 프로그래밍 영어 (2)
- 코테 (5)
- 면접준비 (33)
- 웹사이트 아이디어 비공개 (1)
- 정보처리기사(기본 CS 정보정리) (0)
- 백준 (1)
- 기타 (56)
- 도서 내용 정리 (27)
- 삽질로그 (2)
- PREPLY (1)
- TRAVEL (0)
- DIARY (4)
- OVERSEAS SALES (143)
- PERSONAL (1)
- PROGRAMMING (439)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 미국영어연음
- 우레탄지퍼
- 엑셀자동서식
- 웹API
- AATCC
- 고급영어단어
- 비리짐
- 핸드캐리쿠리어차이점
- 미니마카
- 지연환가료
- 요척합의
- TACKING
- 헤이큐
- 암홀트롭
- WHATTIMEOFTHEDAY
- 와끼
- 40HQ컨테이너40GP컨테이너차이
- 필터링후복사붙여넣기
- 봉제용어
- 엑셀필터복사붙여넣기
- 엑셀드래그단축키
- 자켓실측
- 슈퍼코딩
- 클린코드
- 비슬론지퍼
- 나일론지퍼
- 영어시간읽기
- MERN스택
- 40HQ컨테이너
- Armhole Drop
- Today
- Total
CASSIE'S BLOG
77강 SQL문 JOIN 익히기 본문



LIMIT 1; 이라는 거는 TOP1 만 뽑는거다.


보통 기준테이블-참조테이블 이런 식으로 많이 이야기한다고함.
Inner Join: 두 테이블의 겹치는 부분을 리턴하는 조인
내부 조인 문법
SELECT {컬럼 목록}
FROM {기준 테이블}
INNER JOIN {조인 대상 테이블}
ON {조인될 조건}
{WHERE 검색 조건}
SELECT {컬럼 목록}
FROM {기준 테이블}
JOIN {조인 대상 테이블}
ON {조인될 조건}
{WHERE 검색 조건}
Alias 쓸 때 테이블의 맨앞쪽 글자를 따서 쓴다.
group_singer G 이런 식
Inner join 실습 있음 건너뜀
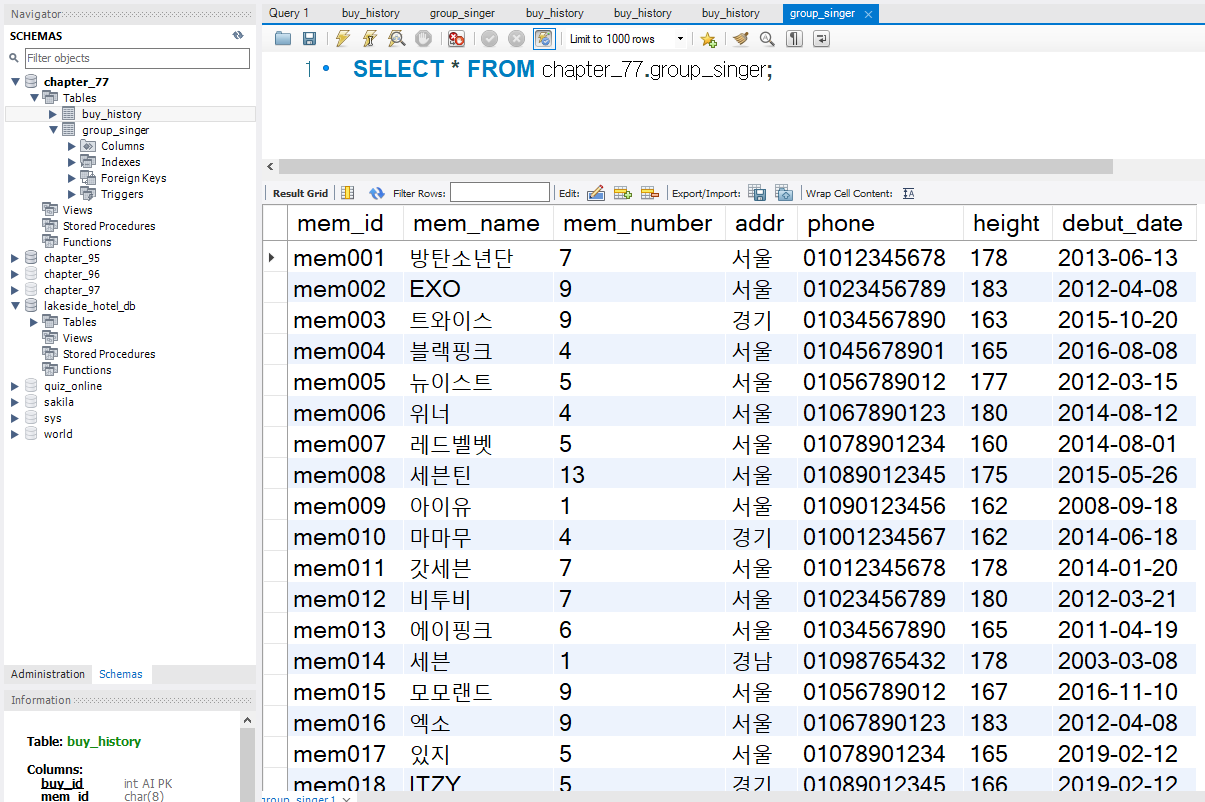
외래키를 가지고 있지않은 테이블이 기준테이블이 된다.

데이터베이스 > 스키마
CREATE DATABASE chapter_77;
USE chapter_77;
스키마와 데이터베이스는 서로 다른 개념입니다. 스키마는 데이터베이스 내에서 데이터를 구조적으로 조직하고 관리하는 논리적인 단위이고, 데이터베이스는 이러한 스키마들을 포함하는 더 큰 컨테이너입니다.
간단히 정리하자면:
데이터베이스는 데이터를 저장하고 관리하는 물리적 컨테이너입니다. 여러 개의 스키마를 포함할 수 있습니다.
스키마는 데이터베이스 내에서 테이블, 뷰, 인덱스, 프로시저 등 데이터베이스 객체들을 그룹화하고 구조화하는 논리적인 구조입니다.
예를 들어:
데이터베이스: chapter_77라는 데이터베이스를 만들면, 이는 전체 데이터를 저장하고 관리하는 공간입니다.
스키마: 그 안에서 여러 개의 스키마를 만들어 각각 다른 목적에 맞는 테이블이나 객체들을 조직할 수 있습니다. 예를 들어, sales_schema, inventory_schema 같은 스키마들이 있을 수 있습니다.
데이터베이스와 스키마는 계층적으로 조직된 개념으로, 스키마는 데이터베이스의 일부입니다.
chapter_77_ddl
CREATE DATABASE chapter_77;
USE chapter_77;
CREATE TABLE group_singer (
mem_id CHAR(8) NOT NULL PRIMARY KEY, -- 가수 ID
mem_name VARCHAR(10) NOT NULL, -- 이름
mem_number INT NOT NULL, -- 인원 수
addr VARCHAR(2) NOT NULL, -- 주소(경기, 서울, 경남 식으로 2글자 입력)
phone VARCHAR(11), -- 전화번호 (하이픈 제외)
height SMALLINT, -- 평균 키
debut_date DATE -- 데뷔
);
CREATE TABLE buy_history (
buy_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, -- 순번(PK)
mem_id CHAR(8) NOT NULL, -- 아이디(FK)
prod_name CHAR(6) NOT NULL, -- 제품 이름
group_name CHAR(4), -- 분류
price INT NOT NULL, -- 단가
amount SMALLINT NOT NULL, -- 수량
FOREIGN KEY (mem_id) REFERENCES group_singer(mem_id)
);
SQL에서 --는 한 줄 주석을 나타냅니다.
buy_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY는:
buy_id가 비어 있을 수 없고(NOT NULL),
정수형(INT)으로 값을 저장하며,
새로운 레코드가 추가될 때마다 자동으로 값이 증가(AUTO_INCREMENT)하고,
buy_id가 기본 키(PRIMARY KEY)로 작동하여 테이블의 각 행을 고유하게 식별합니다.


chapter77_insert_singer
USE chapter_77;
INSERT INTO group_singer (mem_id, mem_name, mem_number, addr, phone, height, debut_date)
VALUES
-- 서울
('mem001', '방탄소년단', 7, '서울', '01012345678', 178, '2013-06-13'),
('mem002', 'EXO', 9, '서울', '01023456789', 183, '2012-04-08'),
('mem004', '블랙핑크', 4, '서울', '01045678901', 165, '2016-08-08'),
('mem005', '뉴이스트', 5, '서울', '01056789012', 177, '2012-03-15'),
('mem006', '위너', 4, '서울', '01067890123', 180, '2014-08-12'),
('mem007', '레드벨벳', 5, '서울', '01078901234', 160, '2014-08-01'),
('mem008', '세븐틴', 13, '서울', '01089012345', 175, '2015-05-26'),
('mem009', '아이유', 1, '서울', '01090123456', 162, '2008-09-18'),
('mem011', '갓세븐', 7, '서울', '01012345678', 178, '2014-01-20'),
('mem012', '비투비', 7, '서울', '01023456789', 180, '2012-03-21'),
('mem013', '에이핑크', 6, '서울', '01034567890', 165, '2011-04-19'),
('mem015', '모모랜드', 9, '서울', '01056789012', 167, '2016-11-10'),
('mem016', '엑소', 9, '서울', '01067890123', 183, '2012-04-08'),
('mem017', '있지', 5, '서울', '01078901234', 165, '2019-02-12'),
('mem019', 'TXT', 5, '서울', '01090123456', 179, '2019-03-04'),
('mem020', 'NCT', 23, '서울', '01001234567', 176, '2016-04-09'),
('mem021', '오마이걸', 7, '서울', '01012345678', 165, '2015-04-20'),
('mem022', '스트레이 키즈', 8, '서울', '01023456789', 172, '2018-03-26'),
('mem023', '에버글로우', 6, '서울', '01034567890', 168, '2019-03-18'),
('mem025', '소녀시대', 8, '서울', '01056789012', 165, '2007-08-05'),
('mem026', '워너원', 11, '서울', '01067890123', 174, '2017-08-07'),
('mem027', '오마이걸', 7, '서울', '01078901234', 165, '2015-04-20'),
('mem029', '몬스타엑스', 7, '서울', '01090123456', 181, '2015-05-14'),
-- 경기
('mem003', '트와이스', 9, '경기', '01034567890', 163, '2015-10-20'),
('mem010', '마마무', 4, '경기', '01001234567', 162, '2014-06-18'),
('mem018', 'ITZY', 5, '경기', '01089012345', 166, '2019-02-12'),
-- 경상도
('mem014', '세븐', 1, '경남', '01098765432', 178, '2003-03-08'),
-- 전라도
('mem024', '박진영', 1, '전남', '01087654321', 180, '1992-09-24'),
-- 충청도
('mem028', '트레저', 12, '충북', '01076543210', 176, '2020-08-07');
chapter77_buy_history_insert
-- buy_history 테이블에 새로운 데이터 삽입
USE chapter_77;
INSERT INTO buy_history (mem_id, prod_name, group_name, price, amount)
VALUES
('mem001', '아메리카노', '음료', 2500, 2),
('mem001', '샌드위치', '식품', 3500, 1),
('mem002', '요구르트', '음료', 1500, 3),
('mem002', '샐러드', '식품', 5000, 1),
('mem003', '핫도그', '식품', 2500, 2),
('mem003', '아이스크림', '간식', 2000, 3),
('mem004', '커피', '음료', 3000, 2),
('mem004', '과자', '간식', 2000, 4),
('mem005', '스포츠 음료', '음료', 3500, 1),
('mem005', '새우깡', '간식', 1500, 2),
('mem006', '콜라', '음료', 2000, 2),
('mem006', '떡볶이', '식품', 3000, 1),
('mem007', '사이다', '음료', 1800, 4),
('mem007', '과일', '식품', 4000, 1),
('mem008', '커피라떼', '음료', 3000, 3),
('mem008', '감자칩', '간식', 2500, 2),
('mem009', '차', '음료', 1500, 1),
('mem009', '파이', '간식', 3000, 1),
('mem010', '코코아', '음료', 2000, 2),
('mem010', '새우튀김', '간식', 3500, 3),
('mem011', '햄버거', '음식', 5000, 1),
('mem011', '피자', '음식', 6000, 2),
('mem012', '샌드위치', '식품', 3500, 1),
('mem012', '과일 주스', '음료', 3000, 3),
('mem013', '과자', '간식', 2000, 2),
('mem013', '커피젤리', '간식', 2500, 1),
('mem014', '라면', '식품', 2500, 3),
('mem014', '스포츠 음료', '음료', 3500, 2),
('mem015', '과일', '식품', 4000, 1),
('mem015', '아이스크림', '간식', 2000, 4),
('mem001', '아메리카노', '음료', 2500, 2),
('mem001', '샌드위치', '식품', 3500, 1),
('mem002', '요구르트', '음료', 1500, 3),
('mem002', '샐러드', '식품', 5000, 1),
('mem003', '핫도그', '식품', 2500, 2),
('mem003', '아이스크림', '간식', 2000, 3),
('mem004', '커피', '음료', 3000, 2),
('mem004', '과자', '간식', 2000, 4),
('mem005', '스포츠 음료', '음료', 3500, 1),
('mem005', '새우깡', '간식', 1500, 2),
('mem006', '콜라', '음료', 2000, 2),
('mem006', '떡볶이', '식품', 3000, 1),
('mem007', '사이다', '음료', 1800, 4),
('mem007', '과일', '식품', 4000, 1),
('mem008', '커피라떼', '음료', 3000, 3),
('mem008', '감자칩', '간식', 2500, 2),
('mem009', '차', '음료', 1500, 1),
('mem009', '파이', '간식', 3000, 1),
('mem010', '코코아', '음료', 2000, 2),
('mem010', '새우튀김', '간식', 3500, 3),
('mem011', '햄버거', '음식', 5000, 1),
('mem011', '피자', '음식', 6000, 2),
('mem012', '샌드위치', '식품', 3500, 1),
('mem012', '과일 주스', '음료', 3000, 3),
('mem013', '과자', '간식', 2000, 2),
('mem013', '커피젤리', '간식', 2500, 1),
('mem014', '라면', '식품', 2500, 3),
('mem014', '스포츠 음료', '음료', 3500, 2),
('mem015', '과일', '식품', 4000, 1),
('mem015', '아이스크림', '간식', 2000, 4);
기준테이블부터 데이터 먼저 만들어야함.


Database > Reverse Engineer
이걸로 이 순서대로 가면 테이블구조 볼 수 있음





JOIN이 (INNER) JOIN 이게 생략된거라고 함.
나는 여기서 끝나는줄 알았는데 붙여줄때는 어디로 붙이는지 이야기를 해야한다고함
대부분 외래키인 FOREIGN KEY를 ON 뒤에 넣어준다고함.
SELECT *
FROM group_singer
JOIN buy_history
뒤에 ON를 안 적으면 실행이 안되는 줄 알았는데 실행이 되긴 함.

ON 부분을 넣은 버전
SELECT *
FROM group_singer
INNER JOIN buy_history
ON group_singer.mem_id = buy_history.mem_id;

SQL에서는 FOREIGN KEY를 정의해도 JOIN 시 ON 절을 자동으로 설정하지 않습니다.
즉, FOREIGN KEY는 데이터베이스 내에서 참조 무결성을 보장하기 위한 제약 조건일 뿐이고, 테이블 간의 관계를 자동으로 인식해 JOIN 시 ON 절을 생략하고 외래 키 기준으로 조인해 주지는 않습니다.
결론:
ON 절을 명시하지 않으면 SQL은 외래 키를 기준으로 자동으로 조인하지 않고, 두 테이블의 카티션 곱을 수행하게 됩니다.
JOIN을 사용할 때는 항상 어떤 컬럼을 기준으로 조인할 것인지를 ON 절에서 명시적으로 지정해야 합니다.
이렇게 직접적으로 ON 절을 써야만 두 테이블을 mem_id를 기준으로 조인할 수 있습니다.
카티션곱
카티션 곱(Cartesian Product)은 두 테이블의 모든 조합을 반환하는 것을 말해요. 쉽게 말하면, 한 테이블의 각 행이 다른 테이블의 모든 행과 짝을 이루는 것이에요. 예를 들어, 두 테이블이 각각 3개의 행을 가지고 있으면, 결과적으로 3 x 3 = 9개의 조합이 생기는 거죠.


카티션 곱을 사용하면 두 테이블에서 같은 이름의 열이 중복됩니다. 예시에서 group_singer와 buy_history 테이블 모두에 mem_id라는 열이 있기 때문에, 결과에는 중복된 열이 두 번 표시됩니다.
JOIN문 뒤에 buy_history B 이렇게 alias 그냥 B 설정가능하다.


내 꺼
SELECT group_singer.mem_id, group_singer_name
FROM group_singer
INNER JOIN buy_history
ON group_singer.mem_id=buy_history.mem.id
WHERE price>1000
HAVING SUM(price) > 5000
LIMIT 3
아 이거를 못했어
SUM를 하기 전에 GROUP BY 를 먼저 지정을 해야한다고함.
일단 member들의 id로 그룹을 먼저 만든다.
같은 멤버들이 구매한 비용을 합쳐야될 것 같고요.
그리고 SUM(B.price) 는 기니까 엘리아스를 써서 AS total_price로 명명
HAVING으로 그룹화된 것들 조건으로 또 걸고
ORDER는 애스캔딩이 기본이기 떄문에 디스켄딩으로 바꾸고
TOP3니까 LIMIT 3;
정답
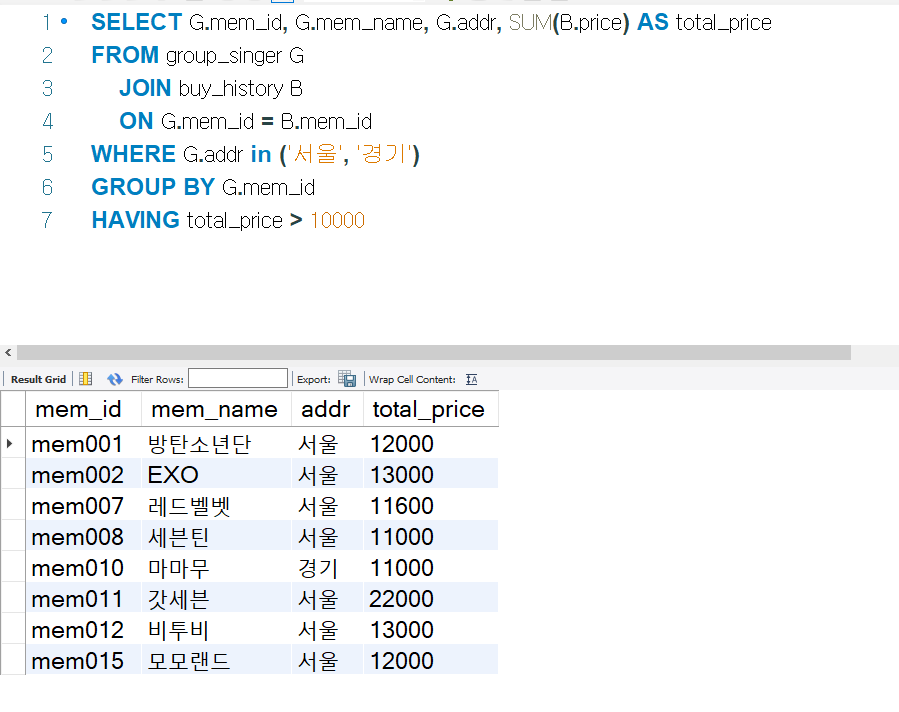
SELECT G.mem_id, G.mem_name,
SUM(B.price) as total_price
FROM group_singer G
INNER JOIN buy_history B
ON G.mem_id = B.mem_id
WHERE B.price > 1000
GROUP BY B.mem_id
HAVING total_price > 5000
ORDER BY total_price DESC
LIMIT 3;
SELECT 절에 **SUM**과 같은 집계 함수가 필수적으로 들어가야 하는 상황은 아닙니다. 하지만 **집계 함수(SUM, COUNT, AVG 등)**를 사용하는 경우, GROUP BY 절과 함께 사용되는 것이 일반적입니다. 이때, 집계되지 않은 열들은 GROUP BY 절에 명시되어야 해요.
DESC와 ASC는 SQL에서 정렬 순서를 나타내는 약어입니다.
- DESC: Descending의 줄임말로, 내림차순을 의미합니다. 큰 값에서 작은 값으로 정렬할 때 사용됩니다. 발음은 **"디센딩"**입니다.
- ASC: Ascending의 줄임말로, 오름차순을 의미합니다. 작은 값에서 큰 값으로 정렬할 때 사용됩니다. 발음은 **"어센딩"**입니다.



내가 푼 것
SELECT G.mem_name, SUM(B.price) AS total_price
FROM group_singer G
INNER JOIN buy_history B
ON G.mem_id = B.mem_id
WHERE G.addr = "서울" OR G.addr = "경기"
GROUP BY G.mem_name
HAVING total_price > 10000
정답:
SELECT COUNT(*)
FROM (
SELECT G.mem_id, G.mem_name,
SUM(B.price)
FROM group_singer G
INNER JOIN buy_history B
ON G.mem_id = B.mem_id
WHERE G.addr IN ('서울', '경기')
GROUP BY G.mem_id
HAVING SUM(B.price) > 10000
) SUB
;
좀 복잡해서 잘라야한다고함
1. 서울/경기 출신 그룹 중 소모한 비용 SUM이 10000원이 넘는 그룹
2. 몇 명
소모한 비용을 일단 구해야하니까
JOIN으로 BUY HISTORY를 일단 구해와야함
GROUP BY는 항상 FOREIGN KEY를 기준으로 많이 묶는다고들 함.
SUM은 뭐 알거고.. 조건 10000원 이사 인거랑 ALIAS 하는 거는...
서울/경기 출신 그룹 중이니까 이게 우선순위라서 WHERE 더 위로
여기까지 하는게 이 쿼리임.
WHERE문은 항상 GROUP보다 앞에 있다.
WHERE G.addr in ('서울'. '경기')
내 쿼리랑 다른 점
1. WHERE 절 / WHERE G.addr in ('서울'. '경기')
2. SELECT문 G.mem_id (foreign key)기준으로 안 가져온 것도 다름. addr 안 가져온 것도 다름
3. GROUP BY를 보통 FOREIGN KEY 기준으로 하는데 나는 MEMBER_NAME 기준으로 GROUP BY한것도 다름.
어떻게 몇명인지 세지? 또 GROUP BY하는거는 아니라고함
설명을 안했었는데 서브쿼리로 하면 쉽게 해결된다고함.
1차 쿼리 자체는 한 개 결과의 테이블로 보고
이거를 FROM으로 넣으면 된다고함.


SELECT COUNT(*)
FROM (
SELECT G.mem_id, G.mem_name,
SUM(B.price)
FROM group_singer G
INNER JOIN buy_history B
ON G.mem_id = B.mem_id
WHERE G.addr IN ('서울', '경기')
GROUP BY G.mem_id
HAVING SUM(B.price) > 10000
) SUB
;

'PROGRAMMING > 슈퍼코딩 강의 정리' 카테고리의 다른 글
| 78-2강 MySQL 제약조건 익히기 (8) | 2024.10.03 |
|---|---|
| 78-1강 MySQL 제약조건 익히기 (0) | 2024.10.02 |
| 슈퍼코딩 105강 Spring boot와 테스팅v2 (0) | 2024.09.28 |
| 가이드 4강 Http쿠키 & 섹션과 jwt (0) | 2024.06.10 |
| 109강 가이드 3강 HTTP 캐싱과 스프링 부트 캐싱 (0) | 2024.05.27 |


