
- 분류 전체보기 (654)

- PROGRAMMING (429)
- JAVA (11)
- JAVA SPRING (13)
- PYTHON (0)
- JAVASCRIPT (21)
- React (70)
- HTML (0)
- Next.JS (1)
- CSS (2)
- DB (Oracle, MongoDB, etc.) (1)
- 깃허브 (31)
- 백엔드 (2)
- 프로젝트 (24)
- 슈퍼코딩 강의 정리 (125)
- ERROR (5)
- 단축키 기타 (1)
- 리눅스 (2)
- LEETCODE (1)
- 정보처리기사 (1)
- 프로그래밍 영어 (2)
- 코테 (5)
- 면접준비 (33)
- 웹사이트 아이디어 비공개 (1)
- 정보처리기사(기본 CS 정보정리) (0)
- 백준 (1)
- 기타 (56)
- 도서 내용 정리 (17)
- 삽질로그 (2)
- PREPLY (1)
- TRAVEL (0)
- DIARY (4)
- OVERSEAS SALES (142)
- PERSONAL (1)
- PROGRAMMING (429)
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 비슬론지퍼
- 헤이큐
- 나일론지퍼
- 엑셀드래그단축키
- 웹API
- AATCC
- 영어시간읽기
- 미니마카
- 비리짐
- 40HQ컨테이너40GP컨테이너차이
- 필터링후복사붙여넣기
- WHATTIMEOFTHEDAY
- MERN스택
- 고급영어단어
- 미국영어연음
- 봉제용어
- 엑셀자동서식
- 암홀트롭
- 핸드캐리쿠리어차이점
- 슈퍼코딩
- 클린코드
- 40HQ컨테이너
- 자켓실측
- 엑셀필터복사붙여넣기
- 지연환가료
- 요척합의
- TACKING
- Armhole Drop
- 와끼
- 우레탄지퍼
Archives
- Today
- Total
CASSIE'S BLOG
[슈퍼코딩] 75-1강 SQL 기본문법 익히기 V2 본문
반응형
트랜잭션: 데이터 처리 원자성을 보장하기 위한 여러 작업 -> 하나의 작업으로 묶는 것

스키마를 변경하는 DDL
DATA를 변경하는 DML
DB에서 DDL과 DML은 각각 다른 종류의 SQL 명령어 그룹을 나타내며, 중간에 들어가는 D와 M은 다음을 의미합니다.
- DDL: Data Definition Language
- DDL의 D는 Definition을 의미합니다.
- 스키마 또는 데이터베이스 구조를 정의(Definition)하는 데 사용되는 명령어들로, 테이블을 생성, 수정, 삭제하는 명령어들이 포함됩니다.
- 예: CREATE, ALTER, DROP, TRUNCATE
- DML: Data Manipulation Language
- DML의 M은 Manipulation을 의미합니다.
- 데이터베이스 내의 실제 데이터를 조작(Manipulation)하는 명령어들로, 데이터를 추가, 수정, 삭제, 조회하는 데 사용됩니다.
- 예: SELECT, INSERT, UPDATE, DELETE
요약:
- DDL: 데이터 구조를 정의하는 명령어 (스키마 변경)
- DML: 데이터를 조작하는 명령어 (데이터 변경)
1. CREATE:
- 역할: 테이블이나 데이터베이스, 인덱스, 뷰 같은 새로운 객체를 생성하는 데 사용됩니다.
- 예시:
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
위 예시는 students라는 테이블을 새로 만드는 명령입니다.
2. ALTER:
- 역할: 기존 테이블이나 다른 객체의 구조를 수정하는 데 사용됩니다.
- 할 수 있는 작업: 컬럼 추가, 삭제, 수정, 데이터 타입 변경 등.
- 예시:
ALTER TABLE students ADD email VARCHAR(100);
위 예시는 students 테이블에 email이라는 새 컬럼을 추가하는 명령입니다.
3. DROP:
- 역할: 테이블, 데이터베이스 등의 전체 객체를 삭제하는 데 사용됩니다.
- 주의할 점: DROP을 실행하면 해당 객체와 그 안의 모든 데이터가 영구적으로 삭제됩니다. 되돌릴 수 없습니다.
- 예시:
DROP TABLE students;
위 명령은 students 테이블과 그 안의 모든 데이터를 삭제합니다.
4. TRUNCATE:
- 역할: 테이블 내의 모든 데이터를 삭제하지만, 테이블 구조는 남겨둡니다.
- 차이점:
- TRUNCATE는 데이터를 삭제하지만 테이블 자체는 유지됩니다.
- 롤백 불가: 데이터를 삭제한 후 되돌리기 어렵습니다.
- 빠름: TRUNCATE는 DELETE보다 훨씬 빠르게 작동하며, 테이블의 모든 데이터를 삭제하는 데 최적화되어 있습니다.
- 예시:
TRUNCATE TABLE students;
-
- students 테이블의 모든 데이터를 삭제하지만, 테이블 자체는 남겨둡니다.
차이점 요약:
- CREATE: 테이블을 새로 만듦.
- ALTER: 기존 테이블의 구조를 수정함.
- DROP: 테이블이나 객체를 완전히 삭제함.
- TRUNCATE: 테이블 내 데이터를 모두 삭제하되, 테이블 구조는 남겨둠.
테이블을 삭제하는 명령(DROP TABLE)은 롤백이 안 된다고 생각하시면 됩니다. 테이블 삭제는 데이터베이스 구조 자체를 변경하는 것이기 때문에, 일반적으로 복구할 수 없는 작업입니다.

구문작성순서와 내부실행순서는 다르다는걸 알아야함.
SELECT 구문을 실행할 때, 내부적으로 처리되는 실제 순서는 아래와 같습니다. SQL을 실행할 때 데이터베이스가 데이터를 처리하는 순서를 기준으로 설명드리겠습니다:
- FROM
먼저 데이터베이스는 어느 테이블에서 데이터를 가져올지 결정합니다.- 예: FROM employees
employees 테이블에서 데이터를 가져옵니다.
- 예: FROM employees
- WHERE
테이블에서 특정 조건을 만족하는 행(row) 만 남깁니다. 이 단계에서 데이터는 필터링됩니다.- 예: WHERE age > 30
나이가 30보다 큰 직원만 남깁니다.
- 예: WHERE age > 30
- GROUP BY
데이터를 특정 열(column) 을 기준으로 그룹화 합니다. 이때, 여러 행이 하나의 그룹으로 묶입니다.- 예: GROUP BY department
직원 데이터를 부서별로 그룹화합니다.
- 예: GROUP BY department
- HAVING
그룹화된 데이터에 대해서 추가적인 조건을 적용하여 필터링합니다.- 예: HAVING COUNT(*) > 5
직원 수가 5명 이상인 부서만 남깁니다.
- 예: HAVING COUNT(*) > 5
- SELECT
앞에서 필터링하고 그룹화한 데이터를 선택하여 출력할 열(column)을 결정합니다.- 예: SELECT department, COUNT(*)
부서 이름과 각 부서의 직원 수를 선택하여 결과로 반환합니다.
- 예: SELECT department, COUNT(*)
- ORDER BY
마지막으로 결과 데이터를 정렬합니다. 원하는 기준에 따라 오름차순 또는 내림차순으로 정렬할 수 있습니다.- 예: ORDER BY department ASC
부서 이름을 기준으로 오름차순으로 정렬합니다.
- 예: ORDER BY department ASC
예시:
SELECT department, COUNT(*)
FROM employees
WHERE age > 30
GROUP BY department
HAVING COUNT(*) > 5
ORDER BY department;
이 예시에서 데이터베이스가 처리하는 실제 순서는:
- FROM: employees 테이블에서 데이터를 가져옴
- WHERE: 나이가 30보다 큰 직원만 남김
- GROUP BY: 남은 데이터를 부서별로 그룹화
- HAVING: 직원 수가 5명 이상인 부서만 선택
- SELECT: 부서명과 직원 수를 출력
- ORDER BY: 부서명 기준으로 결과를 정렬
이 순서로 SQL 문이 처리되며, 결과가 반환됩니다.


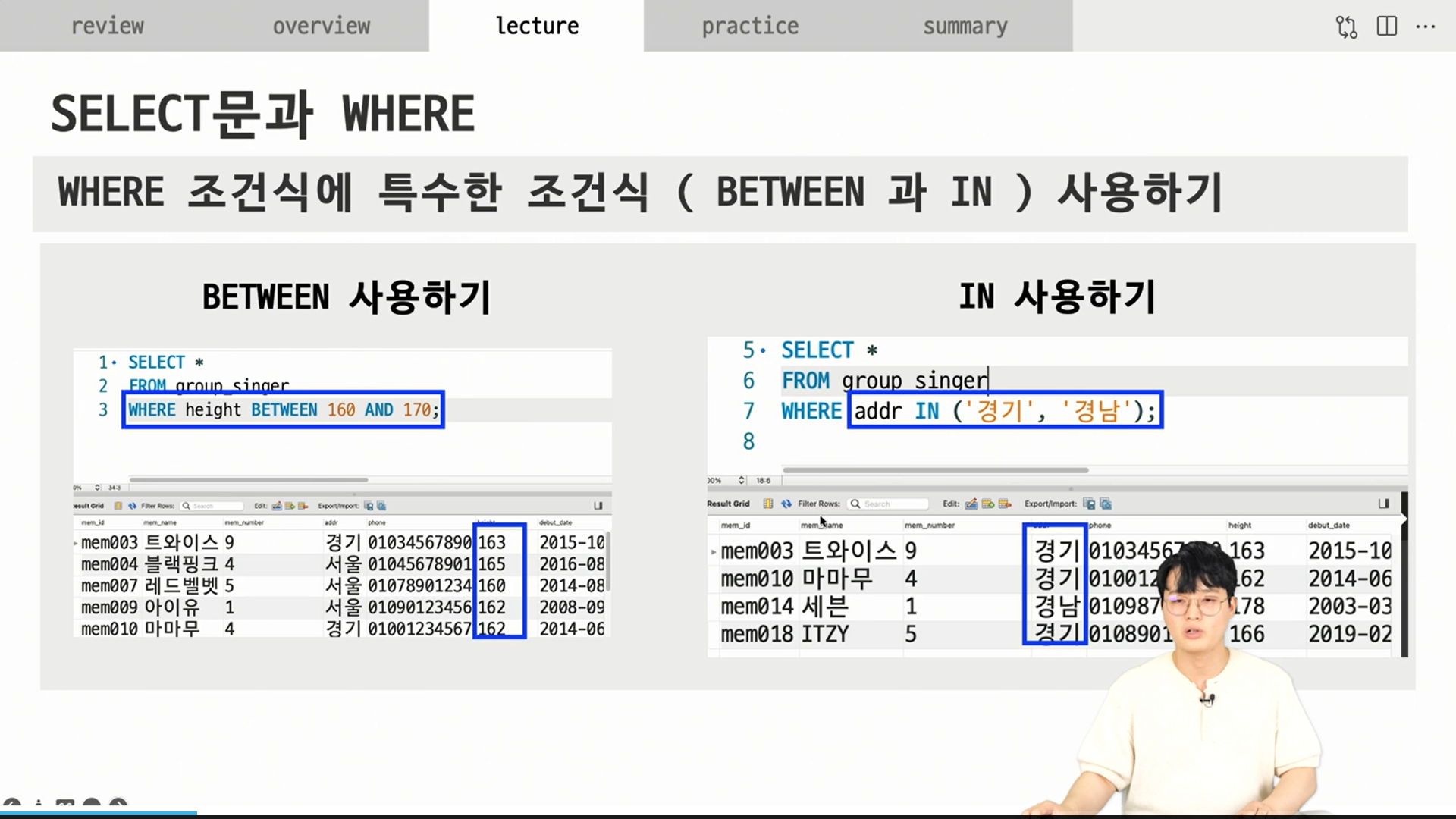
IN이라는 것은 addr 필드가 경기 또는 경남일 때 IN 사용함.
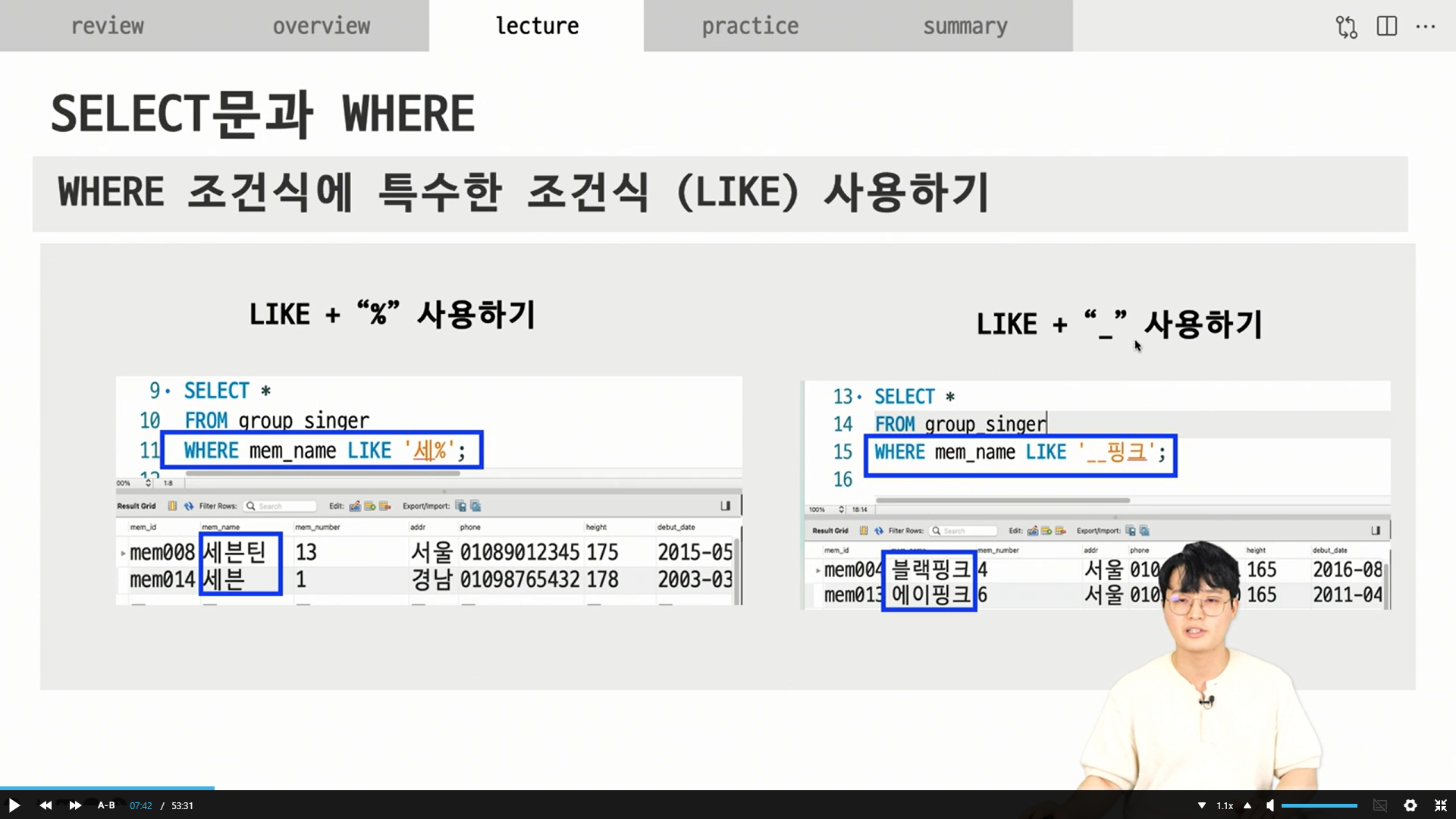
%: 는 뒤에 글자수가 몇개인지 상관없다.
언더바: 그 글자수가 한정되어있다.
실습 건너뜀
반응형
'PROGRAMMING > 슈퍼코딩 강의 정리' 카테고리의 다른 글
| [슈퍼코딩] 96-1강 스프링 부트 실전 적용하기 v1 (Crud 만들기) (0) | 2024.01.26 |
|---|---|
| [슈퍼코딩]95-1강 스프링부트 Service Layer 살펴보기 (0) | 2024.01.26 |
| [슈퍼코딩] 95-1강 스트링 부트 Service Layer 살펴보기 (0) | 2024.01.23 |
| [슈퍼코딩] 94-2강 스트링 부트 Data Access Layer 좀 더 살펴보기 (0) | 2024.01.22 |
| [슈퍼코딩] 94-1강 스트링 부트 Data Access Layer 좀 더 살펴보기 (0) | 2024.01.19 |
'PROGRAMMING/슈퍼코딩 강의 정리' Related Articles
more


